Cache Requests
Request Caching is a premium feature that allows you to cache identical requests made to AI providers. When enabled, Liona will store responses to identical prompts and return the cached result for subsequent identical requests, rather than sending another request to the AI provider.
Request Caching is available exclusively on the Pro plan and requires Request Tracing to be enabled.
Benefits of Request Caching
Implementing Request Caching provides several key advantages:
- Improved Performance: Cached responses are returned instantly, dramatically reducing latency
- Cost Savings: Avoid paying for duplicate requests to AI providers
- Consistency: Ensure identical responses for identical inputs
- Reduced Rate Limiting: Minimize the number of requests sent to AI providers
- Better Development Experience: Speed up testing and development cycles
When to Use Request Caching
Request Caching is particularly valuable in these scenarios:
- Development Environments: Speed up testing cycles with consistent responses
- Deterministic Workflows: Ensure consistent AI behavior for certain inputs
- FAQs and Common Queries: Cache responses to frequently asked questions
- High-Volume Applications: Reduce costs for applications with repetitive queries
- Educational Tools: Provide consistent answers to standard questions
Enabling Request Caching
Enable Request Tracing
Request Caching requires Request Tracing to be enabled first. If you haven’t already done so:
- Navigate to “Policies” in the sidebar
- Edit the policy where you want to enable caching
- Enable “Request Tracing”
Enable Cache Requests
After enabling Request Tracing, toggle “Cache Requests” to the on position.
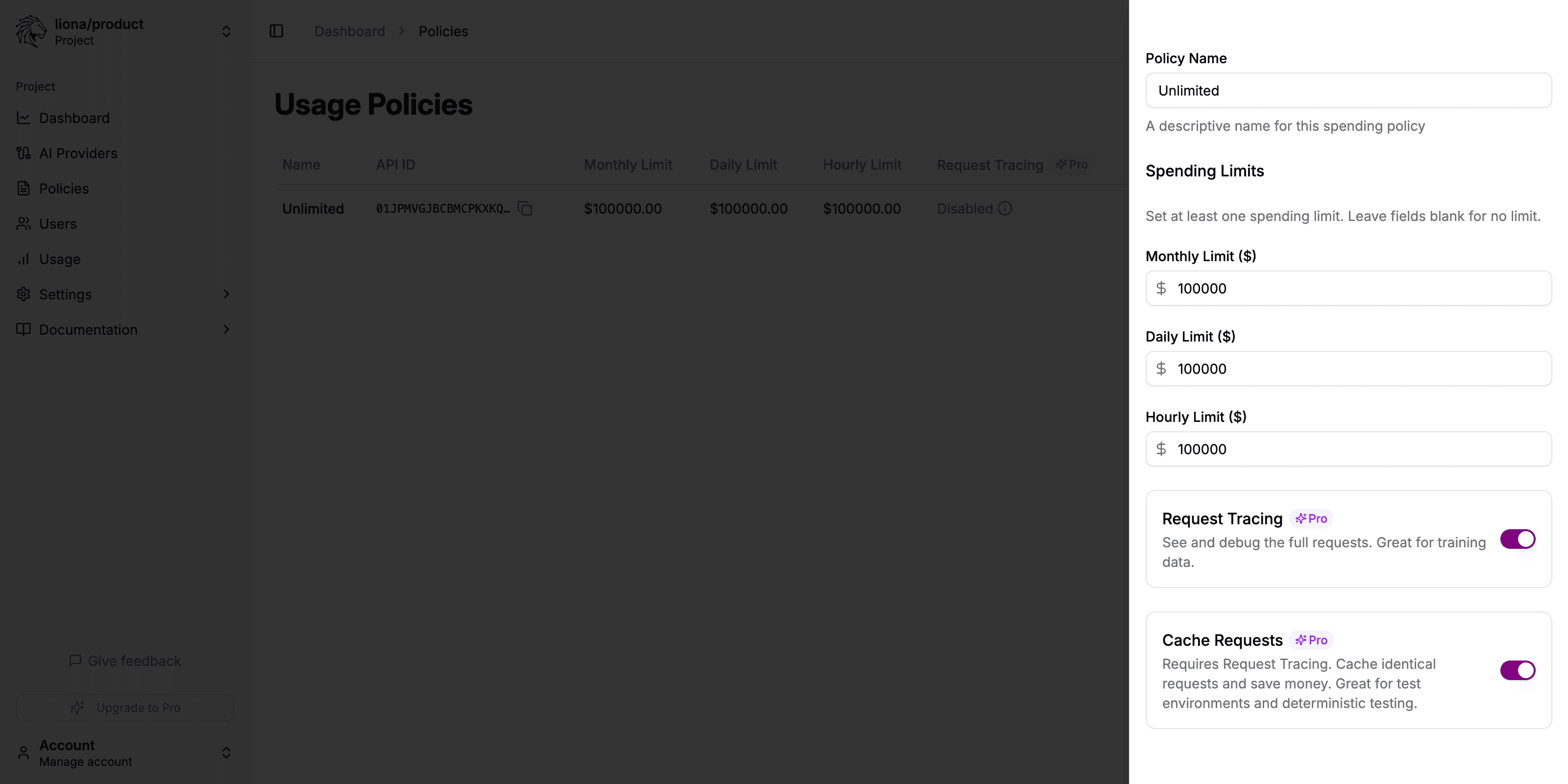
Save Changes
Click “Update Policy” to save your changes. All new requests using this policy will now be cached when possible.
How Request Caching Works
The caching mechanism operates based on these principles:
- Request Matching: When a request exactly matches a previous request (identical prompt and parameters), the cached response is returned
- Request Parameters: Caching considers all parameters (model, temperature, top_p, etc.), not just the prompt text
- Cache Longevity: Cached responses currently remain valid indefinitely (time-based expiration is planned for a future update)
- Model Versioning: Cache is automatically invalidated if the underlying model is updated by the provider
For optimal caching, use deterministic parameters in your requests. For instance, setting temperature: 0 will increase the likelihood of cache hits.
Verifying Cache Usage
You can verify when a cached response is being used:
- Navigate to “Usage” in the sidebar
- Click on a specific execution
- In the detailed view, cached responses will show a “Cached” indicator
- The cost for cached responses is typically zero
Optimizing for Cache Efficiency
To maximize the benefits of Request Caching:
- Standardize Inputs: Preprocess inputs to increase the likelihood of exact matches
- Use Consistent Parameters: Maintain the same model parameters across similar requests
- Set Temperature to Zero: For maximum determinism, set temperature to 0 when possible
- Monitor Cache Hit Rate: Review usage data to understand caching effectiveness
User-Level Cache Settings
You can also enable caching for a specific user:
- Navigate to “Users” and select the user
- Click “Create Policy” in the User Policy section
- Enable “Request Tracing” first
- Then enable “Cache Requests”
- Set an expiration date if this is a temporary change
- Click “Create Policy” to save
This approach is useful for specific users who would benefit from caching, such as developers in testing environments.
Limitations
Be aware of these limitations when using Request Caching:
- Exact Matching Only: Only exactly identical requests will hit the cache
- No Partial Caching: The entire response is cached, partial matching is not supported
- Requires Tracing: Caching requires Request Tracing to be enabled
Next Steps
After enabling Request Caching:
- Monitor your usage to see the cost savings and performance improvements
- Consider tracking usage to measure the impact
- Optimize your application to take advantage of caching with standardized inputs